ĘųŽĒę╗éĆSQLšZŠõā×╗»ĮøÜv
░l▒ĒĢrķgŻ║2023-09-10 üĒį┤Ż║├„▌xšŠš¹└ĒŽÓĻP▄ø╝■ŽÓĻP╬─š┬╚╦ÜŌŻ║
[š¬ę¬]╬ęė├Ą─öĄō■Äņ╩Ūmysql5.6Ż¼Ž┬├µ║åå╬Ą─ĮķĮBŽ┬ł÷Š░šn│╠▒Ēcreate table Course(c_id int PRIMARY KEY,name varchar(10))öĄō■100ŚlīW╔·▒Ē:create table Student(id int PRIMARY KEY,name varchar...
╬ęė├Ą─öĄō■Äņ╩Ūmysql5.6Ż¼Ž┬├µ║åå╬Ą─ĮķĮBŽ┬ł÷Š░
šn│╠▒Ē
create table Course(
c_id int PRIMARY KEY,
name varchar(10)
)
öĄō■100Śl
īW╔·▒Ē:
create table Student(
id int PRIMARY KEY,
name varchar(10)
)
öĄō■70000Śl
īW╔·│╔┐ā▒ĒSC
CREATE table SC(
sc_id int PRIMARY KEY,
s_id int,
c_id int,
score int
)
öĄō■70wŚl
▓ķįā─┐Ą─Ż║
▓ķšęšZ╬─┐╝100ĘųĄ─┐╝╔·
▓ķįāšZŠõŻ║
select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )
ł╠ąąĢrķgŻ║30248.271s
Ģ×,×ķ╩▓├┤▀@├┤┬²Ż¼Ž╚üĒ▓ķ┐┤Ž┬▓ķįāėŗäØŻ║
EXPLAIN
select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )

░l¼Fø]ėąė├ĄĮ╦„ę²Ż¼type╚½╩ŪALLŻ¼─Ū├┤╩ūŽ╚ŽļĄĮĄ─Š═╩ŪĮ©┴óę╗éĆ╦„ę²Ż¼Į©┴ó╦„ę²Ą─ūųČ╬«ö╚╗╩Ūį┌whereŚl╝■Ą─ūųČ╬ĪŻ
Ž╚Įosc▒ĒĄ─c_id║═scoreĮ©éĆ╦„ę²
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);
į┘┤╬ł╠ąą╔Ž╩÷▓ķįāšZŠõŻ¼Ģrķg×ķ: 1.054s
┐ņ┴╦3wČÓ▒ČŻ¼┤¾┤¾┐sČ╠┴╦▓ķįāĢrķgŻ¼┐┤üĒ╦„ę²─▄śO┤¾│╠Č╚Ą─╠ßĖ▀▓ķįāą¦┬╩Ż¼Į©╦„ę²║▄ėą▒žę¬Ż¼║▄ČÓĢr║“Č╝═³ėøĮ©
╦„ę²┴╦Ż¼öĄō■┴┐ąĪĄ─Ą─Ģr║“ē║Ė∙ø]ĖąėXŻ¼▀@ā×╗»Ą─ĖąėX═”╦¼ĪŻ
Ą½╩Ū1sĄ─Ģrķg▀Ć╩Ū╠½ķL┴╦Ż¼▀Ć─▄▀Mąąā×╗»å߯¼ūą╝Ü┐┤ł╠ąąėŗäØŻ║

▓ķ┐┤ā×╗»║¾Ą─sql:
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
WHERE
< in_optimizer > (
`YSB`.`s`.`s_id` ,< EXISTS > (
SELECT
1
FROM
`YSB`.`SC` `sc`
WHERE
(
(`YSB`.`sc`.`c_id` = 0)
AND (`YSB`.`sc`.`score` = 100)
AND (
< CACHE > (`YSB`.`s`.`s_id`) = `YSB`.`sc`.`s_id`
)
)
)
)
ča│õŻ║▀@└’ėąŠWėčå¢į§├┤▓ķ┐┤ā×╗»║¾Ą─šZŠõ
ĘĮĘ©╚ńŽ┬Ż║
į┌├³┴Ņ┤░┐┌ł╠ąą

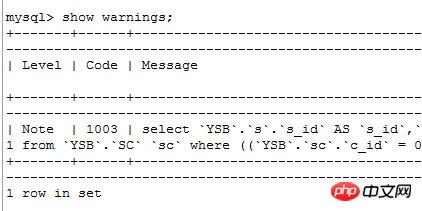
ėątype=all
░┤šš╬ęų«Ū░Ą─ŽļĘ©Ż¼įōsqlĄ─ł╠ąąĄ─Ēśą“æ¬įō╩ŪŽ╚ł╠ąąūė▓ķįā
select s_id from SC sc where sc.c_id = 0 and sc.score = 100
║─ĢrŻ║0.001s
Ą├ĄĮ╚ńŽ┬ĮY╣¹Ż║
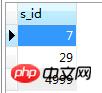
╚╗║¾į┘ł╠ąą
select s.* from Student s where s.s_id in(7,29,5000)
║─ĢrŻ║0.001s
▀@śėŠ═╩ŪŽÓ«ö┐ņ┴╦░ĪŻ¼MysqlŠ╣╚╗▓╗╩ŪŽ╚ł╠ąą└’īėĄ─▓ķįāŻ¼Č°╩Ūīósqlā×╗»│╔┴╦existsūėŠõŻ¼▓ó│÷¼F┴╦EPENDENT SUBQUERYŻ¼
mysql╩ŪŽ╚ł╠ąą═Ōīė▓ķįāŻ¼į┘ł╠ąą└’īėĄ─▓ķįāŻ¼▀@śėŠ═ę¬čŁŁh70007*11=770077┤╬ĪŻ
─Ū├┤Ė─ė├▀BĮė▓ķįā─žŻ┐
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100
▀@└’×ķ┴╦ųžą┬Ęų╬÷▀BĮė▓ķįāĄ─ŪķørŻ¼Ž╚Ģ║Ģräh│²╦„ę²sc_c_id_indexŻ¼sc_score_index
ł╠ąąĢrķg╩ŪŻ║0.057s
ą¦┬╩ėą╦∙╠ßĖ▀Ż¼┐┤┐┤ł╠ąąėŗäØŻ║

▀@└’ėą▀B▒ĒĄ─Ūķør│÷¼FŻ¼╬ę▓┬Žļ╩Ū▓╗╩Ūę¬Įosc▒ĒĄ─s_idĮ©┴óéĆ╦„ę²
CREATE index sc_s_id_index on SC(s_id);
show index from SC
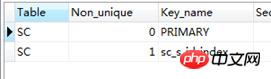
į┌ł╠ąą▀BĮė▓ķįā
Ģrķg: 1.076sŻ¼Š╣╚╗Ģrķg▀ĆūāķL┴╦Ż¼╩▓├┤įŁę“Ż┐▓ķ┐┤ł╠ąąėŗäØŻ║

ā×╗»║¾Ą─▓ķįāšZŠõ×ķŻ║
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
JOIN `YSB`.`SC` `sc`
WHERE
(
(
`YSB`.`sc`.`s_id` = `YSB`.`s`.`s_id`
)
AND (`YSB`.`sc`.`score` = 100)
AND (`YSB`.`sc`.`c_id` = 0)
)
├▓╦Ų╩ŪŽ╚ū÷Ą─▀BĮė▓ķįāŻ¼į┘▀MąąĄ─whereŚl╝■▀^×V
╗žĄĮŪ░├µĄ─ł╠ąąėŗäØŻ║

▀@└’╩ŪŽ╚ū÷Ą─whereŚl╝■▀^×VŻ¼į┘ū÷▀B▒ĒŻ¼ł╠ąąėŗäØ▀Ć▓╗╩Ū╣╠Č©Ą─Ż¼─Ū├┤╬ęéāŽ╚┐┤Ž┬ś╦£╩Ą─sqlł╠ąąĒśą“Ż║

š²│ŻŪķørŽ┬╩ŪŽ╚joinį┘where▀^×VŻ¼Ą½╩Ū╬ęéā▀@└’Ą─ŪķørŻ¼╚ń╣¹Ž╚joinŻ¼īóĢ■ėą70wŚlöĄō■░l╦═joinū÷▓┘Ż¼ę“┤╦Ž╚ł╠ąąwhere
▀^×V╩Ū├„ųŪĘĮ░ĖŻ¼¼Fį┌×ķ┴╦┼┼│²mysqlĄ─▓ķįāā×╗»Ż¼╬ęūį╝║īæę╗Ślā×╗»║¾Ą─sql
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id
╝┤Ž╚ł╠ąąsc▒ĒĄ─▀^×VŻ¼į┘▀Mąą▒Ē▀BĮėŻ¼ł╠ąąĢrķg×ķŻ║0.054s
║═ų«Ū░ø]ėąĮ©s_id╦„ę²Ą─Ģrķg▓Ņ▓╗ČÓ
▓ķ┐┤ł╠ąąėŗäØŻ║

Ž╚╠ß╚Īscį┘▀B▒ĒŻ¼▀@śėą¦┬╩Š═Ė▀ČÓ┴╦Ż¼¼Fį┌Ą─å¢Ņ}╩Ū╠ß╚ĪscĄ─Ģr║“│÷¼F┴╦Æ▀├Ķ▒ĒŻ¼─Ū├┤¼Fį┌┐╔ęį├„┤_ąĶę¬Į©┴óŽÓĻP╦„ę²
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);
į┘ł╠ąą▓ķįāŻ║
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id
ł╠ąąĢrķg×ķŻ║0.001sŻ¼▀@éĆĢrķgŽÓ«ö┐┐ūVŻ¼┐ņ┴╦50▒Č
ł╠ąąėŗäØŻ║

╬ęéāĢ■┐┤ĄĮŻ¼Ž╚╠ß╚ĪscŻ¼į┘▀B▒ĒŻ¼Č╝ė├ĄĮ┴╦╦„ę²ĪŻ
─Ū├┤į┘üĒł╠ąąŽ┬sql
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100
ł╠ąąĢrķg0.001s
ł╠ąąėŗäØŻ║

▀@└’╩Ūmysql▀Mąą┴╦▓ķįāšZŠõā×╗»Ż¼Ž╚ł╠ąą┴╦where▀^×VŻ¼į┘ł╠ąą▀BĮė▓┘ū„Ż¼ŪęČ╝ė├ĄĮ┴╦╦„ę²ĪŻ
┐éĮYŻ║
1.mysqlŪČ╠ūūė▓ķįāą¦┬╩┤_īŹ▒╚▌^Ą═
2.┐╔ęįīóŲõā×╗»│╔▀BĮė▓ķįā
3.▀BĮė▒ĒĢrŻ¼┐╔ęįŽ╚ė├whereŚl╝■ī”▒Ē▀Mąą▀^×VŻ¼╚╗║¾ū÷▒Ē▀BĮė
Ż©ļm╚╗mysqlĢ■ī”▀B▒ĒšZŠõū÷ā×╗»Ż®
4.Į©┴ó║Ž▀mĄ─╦„ę²
5.īWĢ■Ęų╬÷sqlł╠ąąėŗäØŻ¼mysqlĢ■ī”sql▀Mąąā×╗»Ż¼╦∙ęįĘų╬÷ł╠ąąėŗäØ║▄ųžę¬
╦„ę²ā×╗»
╔Ž├µųvĄĮūė▓ķįāĄ─ā×╗»Ż¼ęį╝░╚ń║╬Į©┴ó╦„ę²Ż¼Č°Ūęį┌ČÓéĆūųČ╬╦„ę²ĢrŻ¼Ęųäeī”ūųČ╬Į©┴ó┴╦å╬éĆ╦„ę²
║¾├µ░l¼FŲõīŹĮ©┴ó┬ō║Ž╦„ę²ą¦┬╩Ģ■Ė³Ė▀Ż¼ė╚Ųõ╩Ūį┌öĄō■┴┐▌^┤¾Ż¼å╬éĆ┴ąģ^ĘųČ╚▓╗Ė▀Ą─ŪķørŽ┬ĪŻ
å╬┴ą╦„ę²
▓ķįāšZŠõ╚ńŽ┬Ż║
select * from user_test_copy where sex = 2 and type = 2 and age = 10
╦„ę²Ż║
CREATE index user_test_index_sex on user_test_copy(sex);
CREATE index user_test_index_type on user_test_copy(type);
CREATE index user_test_index_age on user_test_copy(age);
Ęųäeī”sex,type,ageūųČ╬ū÷┴╦╦„ę²Ż¼öĄō■┴┐×ķ300w,▓ķįāĢrķgŻ║0.415s
ł╠ąąėŗäØŻ║

░l¼Ftype=index_merge
▀@╩Ūmysqlī”ČÓéĆå╬┴ą╦„ę²Ą─ā×╗»Ż¼ī”ĮY╣¹╝»▓╔ė├intersect▓ó╝»▓┘ū„
ČÓ┴ą╦„ę²
╬ęéā┐╔ęįį┌▀@3éĆ┴ą╔ŽĮ©┴óČÓ┴ą╦„ę²Ż¼īó▒Ēcopyę╗Ę▌ęį▒Ńū÷£yįć
create index user_test_index_sex_type_age on user_test(sex,type,age);
▓ķįāšZŠõŻ║
select * from user_test where sex = 2 and type = 2 and age = 10
ł╠ąąĢrķgŻ║0.032sŻ¼┐ņ┴╦10ČÓ▒ČŻ¼ŪęČÓ┴ą╦„ę²Ą─ģ^ĘųČ╚įĮĖ▀Ż¼╠ßĖ▀Ą─╦┘Č╚ę▓įĮČÓ
ł╠ąąėŗäØŻ║

ūŅū¾Ū░ŠY
ČÓ┴ą╦„ę²▀ĆėąūŅū¾Ū░ŠYĄ─╠žąįŻ║
ł╠ąąę╗Ž┬šZŠõŻ║
select * from user_test where sex = 2
select * from user_test where sex = 2 and type = 2
select * from user_test where sex = 2 and age = 10
Č╝Ģ■╩╣ė├ĄĮ╦„ę²Ż¼╝┤╦„ę²Ą─Ą┌ę╗éĆūųČ╬sexę¬│÷¼Fį┌whereŚl╝■ųą
╦„ę²Ė▓╔w
Š═╩Ū▓ķįāĄ─┴ąČ╝Į©┴ó┴╦╦„ę²Ż¼▀@śėį┌½@╚ĪĮY╣¹╝»Ą─Ģr║“▓╗ė├į┘╚ź┤┼▒P½@╚ĪŲõ╦³┴ąĄ─öĄō■Ż¼ų▒ĮėĘĄ╗ž╦„ę²öĄō■╝┤┐╔
╚ńŻ║
select sex,type,age from user_test where sex = 2 and type = 2 and age = 10
ł╠ąąĢrķgŻ║0.003s
ę¬▒╚╚Ī╦∙ėąūųČ╬┐ņĄ─ČÓ
┼┼ą“
select * from user_test where sex = 2 and type = 2 ORDER BY user_name
ĢrķgŻ║0.139s
į┌┼┼ą“ūųČ╬╔ŽĮ©┴ó╦„ę²Ģ■╠ßĖ▀┼┼ą“Ą─ą¦┬╩
create index user_name_index on user_test(user_name)
ūŅ║¾ĖĮ╔Žę╗ą®sqlš{āץ─┐éĮYŻ¼ęį║¾ėąĢrķgį┘╔Ņ╚ļ蹊┐
1. ┴ąŅÉą═▒M┴┐Č©┴x│╔öĄųĄŅÉą═Ż¼ŪęķLČ╚▒M┐╔─▄Č╠Ż¼╚ńų„µI║══ŌµIŻ¼ŅÉą═ūųČ╬Ą╚Ą╚
2. Į©┴óå╬┴ą╦„ę²
3. Ė∙ō■ąĶę¬Į©┴óČÓ┴ą┬ō║Ž╦„ę²
«öå╬éĆ┴ą▀^×Vų«║¾▀Ćėą║▄ČÓöĄō■Ż¼─Ū├┤╦„ę²Ą─ą¦┬╩īóĢ■▒╚▌^Ą═Ż¼╝┤┴ąĄ─ģ^ĘųČ╚▌^Ą═Ż¼
─Ū├┤╚ń╣¹į┌ČÓéĆ┴ą╔ŽĮ©┴ó╦„ę²Ż¼─Ū├┤ČÓéĆ┴ąĄ─ģ^ĘųČ╚Š═┤¾ČÓ┴╦Ż¼īóĢ■ėą’@ų°Ą─ą¦┬╩╠ßĖ▀ĪŻ
4. Ė∙ō■śIäšł÷Š░Į©┴óĖ▓╔w╦„ę²
ų╗▓ķįāśIäšąĶꬥ─ūųČ╬Ż¼╚ń╣¹▀@ą®ūųČ╬▒╗╦„ę²Ė▓╔wŻ¼īóśO┤¾Ą─╠ßĖ▀▓ķįāą¦┬╩
5. ČÓ▒Ē▀BĮėĄ─ūųČ╬╔ŽąĶę¬Į©┴ó╦„ę²
▀@śė┐╔ęįśO┤¾Ą─╠ßĖ▀▒Ē▀BĮėĄ─ą¦┬╩
6. whereŚl╝■ūųČ╬╔ŽąĶę¬Į©┴ó╦„ę²
7. ┼┼ą“ūųČ╬╔ŽąĶę¬Į©┴ó╦„ę²
8. ĘųĮMūųČ╬╔ŽąĶę¬Į©┴ó╦„ę²
9. WhereŚl╝■╔Ž▓╗ę¬╩╣ė├▀\╦Ń║»öĄŻ¼ęį├Ō╦„ę²╩¦ą¦
ęį╔ŽŠ═╩ŪĘųŽĒę╗éĆSQLšZŠõā×╗»ĮøÜvĄ─įö╝Üā╚╚▌Ż¼Ė³ČÓšłĻPūóphpųą╬─ŠWŲõ╦³ŽÓĻP╬─š┬ŻĪ
īW┴ĢĮ╠│╠┐ņ╦┘šŲ╬šÅ─╚ļķTĄĮŠ½═©Ą─SQLų¬ūRĪŻ
