MySQLĘųĒōā×(y©Łu)╗»Ą─£yįć░Ė└²
░l(f©Ī)▒ĒĢrķgŻ║2023-09-02 üĒį┤Ż║├„▌xšŠš¹└ĒŽÓĻP(gu©Īn)▄ø╝■ŽÓĻP(gu©Īn)╬─š┬╚╦ÜŌŻ║
[š¬ę¬]ūŅĮ³¤oęŌķg┐┤ĄĮę╗éĆMySQLĘųĒōā×(y©Łu)╗»Ą─£yįć░Ė└²Ż¼▓óø]ėąĘŪ│ŻŠ▀¾wĄžšf├„£yįćł÷Š░Ą─ŪķørŽ┬Ż¼Įo│÷┴╦ę╗ĘNĮø(j©®ng)ĄõĄ─ĘĮ░ĖŻ¼ę“?y©żn)ķ¼F(xi©żn)īŹ(sh©¬)ųą║▄ČÓŪķørČ╝▓╗╩Ū╣╠Č©▓╗ūāĄ─Ż¼─▄┐éĮY(ji©”)│÷üĒ═©ė├ąįĄ─ū÷Ę©╗“š▀šf╩ŪęÄ(gu©®)┬╔Ż¼╩Ūę¬┐╝æ]ĘŪ│ŻČÓĄ─ł÷Š░Ą─Ż¼═¼ĢrŻ¼├µī”─▄ē“▀_(d©ó)ĄĮā×(y©Łu)╗»Ą─ĘĮ╩Įę¬ūĘŠ┐ŲõįŁę“Ż¼═¼śėĄ─ū÷Ę©Ż¼ōQ┴╦éĆł÷Š░Ż¼▀_(d©ó)▓╗ĄĮā×(y©Łu)╗»ą¦╣¹Ą─Ż¼▀Ćę¬ūĘŠ┐Ųõ...
ūŅĮ³¤oęŌķg┐┤ĄĮę╗éĆMySQLĘųĒōā×(y©Łu)╗»Ą─£yįć░Ė└²Ż¼▓óø]ėąĘŪ│ŻŠ▀¾wĄžšf├„£yįćł÷Š░Ą─ŪķørŽ┬Ż¼Įo│÷┴╦ę╗ĘNĮø(j©®ng)ĄõĄ─ĘĮ░ĖŻ¼
ę“?y©żn)ķ¼F(xi©żn)īŹ(sh©¬)ųą║▄ČÓŪķørČ╝▓╗╩Ū╣╠Č©▓╗ūāĄ─Ż¼─▄┐éĮY(ji©”)│÷üĒ═©ė├ąįĄ─ū÷Ę©╗“š▀šf╩ŪęÄ(gu©®)┬╔Ż¼╩Ūę¬┐╝æ]ĘŪ│ŻČÓĄ─ł÷Š░Ą─Ż¼
═¼ĢrŻ¼├µī”─▄ē“▀_(d©ó)ĄĮā×(y©Łu)╗»Ą─ĘĮ╩Įę¬ūĘŠ┐ŲõįŁę“Ż¼═¼śėĄ─ū÷Ę©Ż¼ōQ┴╦éĆł÷Š░Ż¼▀_(d©ó)▓╗ĄĮā×(y©Łu)╗»ą¦╣¹Ą─Ż¼▀Ćę¬ūĘŠ┐ŲõįŁę“ĪŻ
éĆ╚╦ī”┤╦ł÷Š░į┌▓╗ė├Ūķør▒Ē╩Šæčę╔Ż¼╚╗║¾ūį╝║£yįć┴╦ę╗░čŻ¼╣¹╚╗░l(f©Ī)¼F(xi©żn)ę╗ą®å¢Ņ}Ż¼═¼Ģrę▓ūCīŹ(sh©¬)┴╦ę╗ą®ŅA(y©┤)Ų┌Ą─ŽļĘ©ĪŻ
▒Š╬─Š═MySQLĘųĒōā×(y©Łu)╗»Ż¼Å─ūŅūŅ║åå╬Ą─Ūķør│÷░l(f©Ī)Ż¼üĒū÷ę╗éĆ║åå╬Ą─Ęų╬÷ĪŻ
┴ĒŻ║▒Š╬─£yįćŁh(hu©ón)Š│╩ŪūŅūŅĄ═┼õų├Ą─įŲĘ■äš(w©┤)Ų„Ż¼ŽÓī”üĒšfĘ■äš(w©┤)Ų„ė▓╝■Łh(hu©ón)Š│ėąŽ▐Ż¼▓╗▀^ī”ė┌▓╗═¼Ą─šZŠõŻ©īæĘ©Ż®æ¬(y©®ng)įō╩ŪĪ░ŲĮĄ╚Ą─Ī▒
MySQLĮø(j©®ng)ĄõĄ─ĘųĒōĪ░ā×(y©Łu)╗»Ī▒ū÷Ę©
MySQLĘųĒōā×(y©Łu)╗»ųąŻ¼ėąę╗ĘNĮø(j©®ng)ĄõĄ─å¢Ņ}Ż¼į┌▓ķįāįĮĪ░┐┐║¾Ī▒Ą─öĄ(sh©┤)ō■(j©┤)įĮ┬²Ż©╚ĪøQė┌▒Ē╔ŽĄ─╦„ę²ŅÉą═Ż¼ī”ė┌BśõĮY(ji©”)śŗ(g©░u)Ą─╦„ę²Ż¼SQL Serverųąę▓ę╗śėŻ®
select * from t order by id limit m,nĪŻ
ę▓╝┤ļSų°MĄ─į÷┤¾Ż¼▓ķįā═¼śėČÓĄ─öĄ(sh©┤)ō■(j©┤)Ż¼Ģ■įĮüĒįĮ┬²
├µī”▀@ę╗å¢Ņ}Ż¼ė┌╩ŪŠ═«a(ch©Żn)╔·┴╦ę╗ĘNĮø(j©®ng)ĄõĄ─ū÷Ę©Ż¼ŅÉ╦Ųė┌Ż©╗“š▀ūāĘNŻ®╚ńŽ┬Ą─īæĘ©
Š═╩ŪŽ╚░čĘųĒōĘČć·ā╚(n©©i)Ą─idå╬¬Ü(d©▓)šę│÷üĒŻ¼╚╗║¾į┘Ė·╗∙▒Ēū÷ĻP(gu©Īn)┬ō(li©ón)Ż¼ūŅ║¾▓ķįā│÷üĒ╦∙ąĶꬥ─öĄ(sh©┤)ō■(j©┤)
select * from t
inner join (select id from t order by id limit m,n)t1 on t1.id = t.id
▀@ĘNū÷Ę©╩Ū▓╗╩Ū┐é╩Ū╔·ą¦Ą─Ż¼╗“š▀šf╩Ūį┌╩▓├┤ŪķørŽ┬║¾š▀▓┼─▄ĄĮ▀_(d©ó)ĄĮā×(y©Łu)╗»Ą──┐Ą─Ż┐ėąø]ėąū÷┴╦Ė─īæų«║¾¤oą¦╔§ų┴ūā┬²Ą─ŪķørŻ┐
┼c┤╦═¼ĢrŻ¼Į^┤¾ČÓöĄ(sh©┤)▓ķįāČ╝╩Ūėą║Y▀xŚl╝■Ą─Ż¼
╚ń╣¹ėą║Y▀xŚl╝■Ą─ŪķørŻ¼
sqlšZŠõŠ═ūā│╔┴╦select * from t where *** order by id limit m,n
╚ń╣¹╚ńĘ©┼┌ųŲŻ¼Ė─īæ│╔ŅÉ╦Ų
select * from t
inner join (select id from t where *** order by id limit m,n )t1 on t1.id = t.id
į┌▀@ĘNŪķørŽ┬Ż¼Ė─īæ║¾Ą─sqlšZŠõ▀Ć─▄▀_(d©ó)ĄĮā×(y©Łu)╗»Ą──┐Ą─å߯┐
£yįćŁh(hu©ón)Š│┤ŅĮ©
ĪĪĪĪ£yįćöĄ(sh©┤)ō■(j©┤)▒╚▌^║åå╬Ż¼═©▀^┤µā”▀^│╠裣h(hu©ón)īæ╚ļ£yįćöĄ(sh©┤)ō■(j©┤)Ż¼£yįć▒ĒĄ─InnoDBę²Ūµ▒ĒĪŻ
ĪĪĪĪ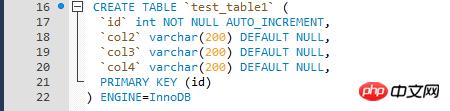
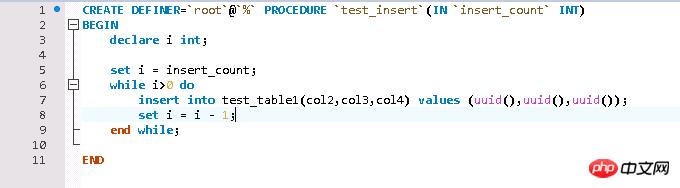
ĪĪĪĪ▀@└’ę¬ūóęŌĄ─╩Ū╚šųŠīæ╚ļ─Ż╩Įę╗ȩꬹ▐Ė─│╔innodb_flush_log_at_trx_commit = 2Ż¼Ę±ät─¼šJ(r©©n)ŪķørŽ┬Ż¼500wöĄ(sh©┤)ō■(j©┤)Ż¼╣└ėŗę╗╠ņČ╝īæ▓╗═ĻŻ¼▀@éĆ┼c╚šųŠīæ╚ļ─Ż╩ĮėąĻP(gu©Īn)Ż¼Š═▓╗ČÓšf┴╦Ż¼

ĘųĒō▓ķįāā×(y©Łu)╗»Ą─Šēė╔
ĪĪĪĪ╩ūŽ╚▀Ć╩ŪŽ╚┐┤ę╗Ž┬▀@éĆĮø(j©®ng)ĄõĄ─å¢Ņ}Ż¼ĘųĒōĄ─Ģr║“Ż¼įĮĪ░┐┐║¾Ī▒▓ķįāŽÓæ¬(y©®ng)įĮ┬²Ą─Ūķør
ĪĪĪĪ£yįćę╗Ż║▓ķįāĄ┌1-20ąąĄ─öĄ(sh©┤)ō■(j©┤)Ż¼0.01├ļ
ĪĪĪĪ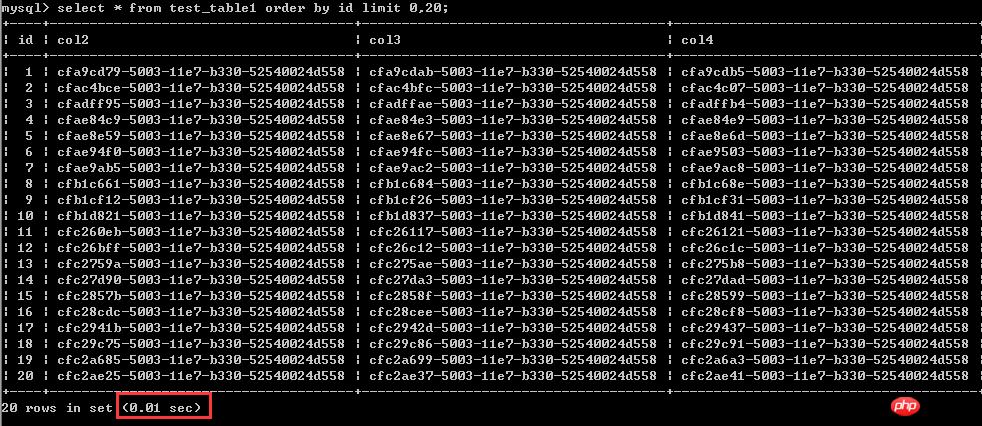
ĪĪĪĪ═¼śė╩Ū▓ķįā20ąąöĄ(sh©┤)ō■(j©┤)Ż¼▓ķįāŽÓī”Ī░┐┐║¾Ī▒Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▒╚╚ń▀@└’Ą─Å─4900001-4900020ąąöĄ(sh©┤)ō■(j©┤)Ą─ŪķørŻ¼ė├Ģr1.97├ļĪŻ
ĪĪĪĪ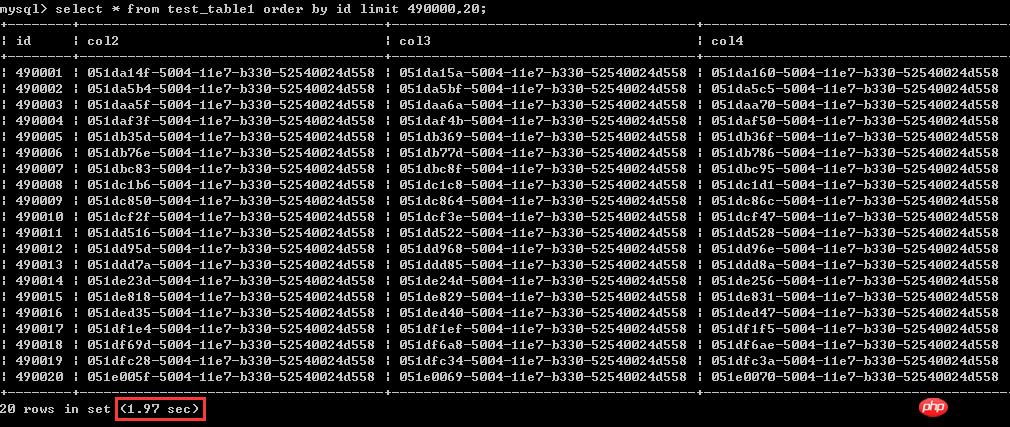
ĪĪĪĪÅ─ųą┐╔ęį┐┤ĄĮŻ¼▓ķįāŚl╝■▓╗ūāĄ─ŪķørŽ┬Ż¼įĮ═∙║¾▓ķįāŻ¼▓ķįāą¦┬╩įĮĄ═Ż¼┐╔ęį║åå╬└ĒĮŌ│╔Ż║═¼śė╦č╦„20ąąöĄ(sh©┤)ō■(j©┤)Ż¼įĮ╩Ū┐┐║¾Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▓ķįā┤·ārįĮ┤¾ĪŻ
ĪĪĪĪų┴ė┌×ķ╩▓├┤║¾ę╗ĘNą¦┬╩▌^Ą═Ż¼║¾├µĢ■┬²┬²Ęų╬÷ĪŻ
ĪĪĪĪ£yįćŁh(hu©ón)Š│╩Ūcentos 7 Ż¼mysql 5.7Ż¼£yįć▒ĒĄ─öĄ(sh©┤)ō■(j©┤)╩Ū500W
ĪĪĪĪ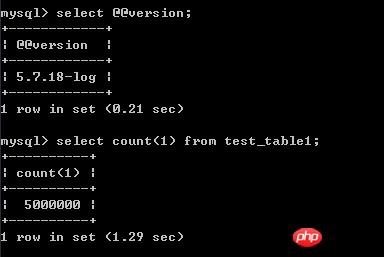
ųž¼F(xi©żn)Įø(j©®ng)ĄõĘųĒōĪ░ā×(y©Łu)╗»Ī▒Ż¼«ö(d©Īng)ø]ėą║Y▀xŚl╝■Ż¼┼┼ą“┴ą×ķŠ█╝»╦„ę²Ą─Ģr║“Ż¼▓ó▓╗Ģ■ėą╦∙Ė─╔Ų
▀@└’üĒī”▒╚ęįŽ┬ā╔ĘNīæĘ©į┌Š█╝»╦„ę²┴ąū„×ķ┼┼ą“Śl╝■Ģr║“Ą─ąį─▄
select * from t order by id limit m,nĪŻ
select * from t
inner join (select id from t order by id limit m,n)t1 on t1.id = t.id
ĪĪĪĪĄ┌ę╗ĘNīæĘ©Ż║
ĪĪĪĪselect * from test_table1 order by id asc limit 4900000,20;£yįćĮY(ji©”)╣¹ęŖĮžłDŻ¼ł╠(zh©¬)ąąĢrķg×ķ8.31├ļ
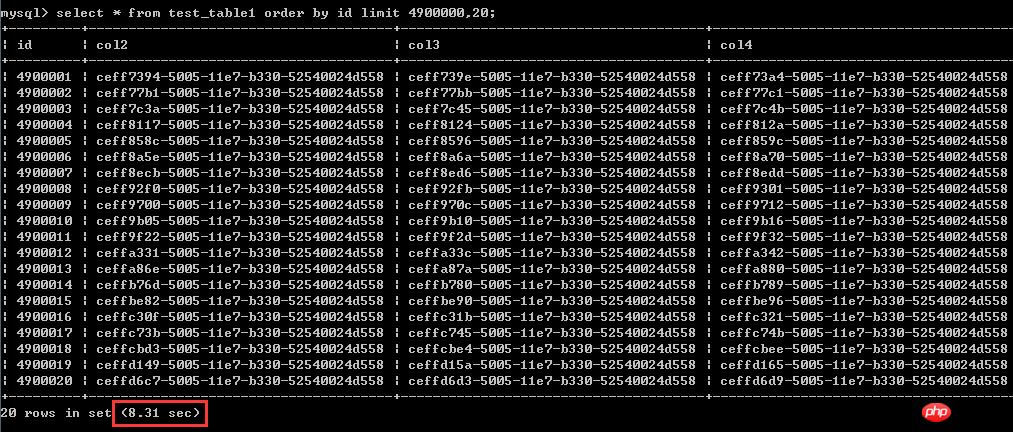
Ą┌Č■ĘNĖ─īæ║¾Ą─īæĘ©Ż║
select t1.* from test_table1 t1
inner join (select id from test_table1 order by id limit 4900000,20)t2 on t1.id = t2.id;ł╠(zh©¬)ąąĢrķg×ķ8.43├ļ
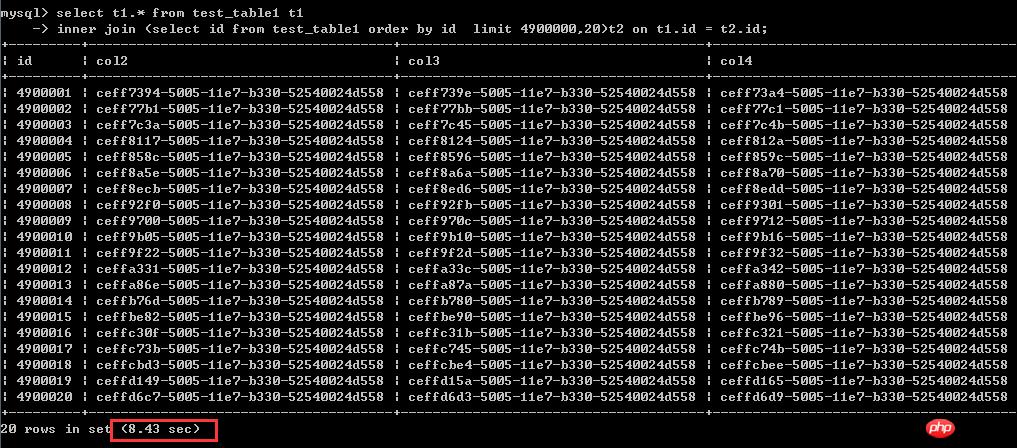
▀@└’║▄ŪÕ│■Ż¼═©▀^Įø(j©®ng)ĄõĄ─Ė─īæĘĮĘ©Ė─īæų«║¾Ż¼ąį─▄─▄║┴¤o╠ß╔²,╔§ų┴▀Ćėąę╗³c(di©Żn)³c(di©Żn)ūā┬²┴╦Ż¼
īŹ(sh©¬)ļH£yįć╔Ž▒Ē¼F(xi©żn)×ķā╔š▀į┌ąį─▄╔Ž▓óø]ėą├„’@Ą─ŠĆąį▓Ņ«ÉŻ¼▀@ā╔š▀śŪų„╩Ūū÷┴╦ČÓ┤╬£yįćĄ─ĪŻ
╬ęéĆ╚╦┐┤ĄĮŅÉ╦ŲĮY(ji©”)šōĘŪę¬£yę╗Ž┬▓╗┐╔Ą─Ż¼▀@éĆ¢|╬„▓╗─▄┐┐├╔Ż¼╗“š▀┐┐▀\(y©┤n)ÜŌ╩▓├┤Ą─Ż¼─▄╠ßĖ▀ą¦┬╩╩Ū×ķ╩▓├┤Ż¼▓╗─▄╠ßĖ▀ėų╩Ū×ķ╩▓├┤ĪŻ
─Ū├┤×ķ╩▓├┤Ė─īæų«║¾Ą─īæĘ©ø]ėąŽ±é„šfųąĄ──ŪĘN╠ß╔²ąį─▄Ż┐
╩Ū╩▓├┤ī¦(d©Żo)ų┬«ö(d©Īng)Ū░▀@éĆĖ─īæø]ėąĄĮ▀_(d©ó)╠ß╔²ąį─▄Ą──┐Ą─Ż┐
║¾š▀─▄ē“╠ß╔²ąį─▄Ą─įŁ└Ē╩Ū╩▓├┤Ż┐
ĪĪĪĪ╩ūŽ╚┐┤ę╗Ž┬£yįć▒ĒĄ─▒ĒĮY(ji©”)śŗ(g©░u)Ż¼┼┼ą“┴ą╔Ž╩Ūėą╦„ę²Ż¼▀@ę╗³c(di©Żn)╩Ūø]ėąå¢Ņ}Ą─Ż¼ĻP(gu©Īn)µI╩Ū▀@éĆ┼┼ą“┴ą╔ŽĄ─╦„ę²╩Ūų„µIŻ©Š█╝»╦„ę²Ż®ĪŻ
ĪĪĪĪ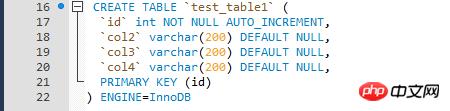
ĪĪĪĪ×ķ╩▓├┤┼┼ą“┴ą╔Ž╩ŪŠ█╝»╦„ę²Ą─Ģr║“Ż¼ŽÓī”Ī░ā×(y©Łu)╗»Ī▒Ė─īæų«║¾Ą─sql▓ó▓╗─▄▀_(d©ó)ĄĮĪ░ā×(y©Łu)╗»Ī▒Ą──┐Ą─?
į┌┼┼ą“┴ą×ķŠ█╝»╦„ę²┴ąĄ─ŪķørŽ┬Ż¼ā╔š▀Č╝╩ŪĒśą“Æ▀├Ķ▒ĒüĒīŹ(sh©¬)¼F(xi©żn)▓ķįāĘ¹║ŽŚl╝■Ą─öĄ(sh©┤)ō■(j©┤)Ą─
║¾š▀ļm╚╗╩ŪŽ╚“ī(q©▒)äėę╗éĆūė▓ķįāŻ¼╚╗║¾į┘ė├ūė▓ķįāĄ─ĮY(ji©”)╣¹“ī(q©▒)äėų„▒ĒŻ¼
Ą½╩Ūūė▓ķįā▓óø]ėąĖ─ūāĪ░Ēśą“Æ▀├Ķ▒ĒüĒīŹ(sh©¬)¼F(xi©żn)▓ķįāĘ¹║ŽŚl╝■Ą─öĄ(sh©┤)ō■(j©┤)Ą─Ī▒ū÷Ę©Ż¼«ö(d©Īng)Ū░ŪķørŽ┬Ż¼╔§ų┴Ė─īæ║¾Ą─ū÷Ę©’@Ą├«ŗ╔▀╠ĒūŃ
ģó┐╝╚ńŽ┬ā╔š▀ł╠(zh©¬)ąąėŗäØŻ¼Ą┌ę╗éĆĮžłDĄ─ł╠(zh©¬)ąąėŗäØĄ─ę╗ąąŻ¼┼cĖ─īæ║¾Ą─sqlĄ─ł╠(zh©¬)ąąėŗäØĄ─Ą┌╚²ąąŻ©id =2 Ą──Ūę╗ąąŻ®Ż¼╗∙▒Š╔Žę╗śėĪŻ
ĪĪĪĪ
ĪĪĪĪ
«ö(d©Īng)ø]ėą║Y▀xŚl╝■Ż¼┼┼ą“┴ą×ķŠ█╝»╦„ę²Ģr║“Ą─ĘųĒō▓ķįāŻ¼╦∙ų^Ą─ĘųĒō▓ķįāā×(y©Łu)╗»ų╗▓╗▀^╩Ū«ŗ╔▀╠ĒūŃ
ĪĪĪĪ─┐Ū░üĒ┐┤Ż¼▓ķįā╔Ž╩÷öĄ(sh©┤)ō■(j©┤)Ż¼ā╔ĘNĘĮ╩ĮČ╝ĘŪ│Ż┬²Ż¼─Ū╚ń╣¹ę¬▓ķįā╔Ž╩÷Ą─öĄ(sh©┤)ō■(j©┤)Ż¼įō╚ń║╬ū÷Ż┐
ĪĪĪĪ▀Ć╩Ūę¬┐┤×ķ╩▓├┤┬²Ż¼╩ūŽ╚ę¬└ĒĮŌBöĄ(sh©┤)Ą─ŲĮ║ŌąįĮY(ji©”)śŗ(g©░u)Ż¼į┌╬ęūį╝║┤ų┬įĄ─└ĒĮŌüĒ┐┤Ż¼╚ńŽ┬łDŻ¼
ĪĪĪĪ«ö(d©Īng)▓ķįāĄ─öĄ(sh©┤)ō■(j©┤)Ī░┐┐║¾Ī▒Ą─Ģr║“Ż¼īŹ(sh©¬)ļH╔Ž╩ŪŲ½ļxį┌Bśõ╦„ę²Ą─ę╗éĆĘĮŽ“Ż¼╚ńŽ┬ā╔éĆĮžłD╦∙╩ŠĄ──┐ś╦(bi©Īo)öĄ(sh©┤)ō■(j©┤)
ĪĪĪĪŲõīŹ(sh©¬)ŲĮ║Ōśõ╔ŽĄ─öĄ(sh©┤)ō■(j©┤)Ż¼ø]ėą╦∙ų^Ą─Ī░┐┐Ū░Ī▒┼cĪ░┐┐║¾Ī▒Ż¼Ī░┐┐Ū░Ī▒┼cĪ░┐┐║¾Ī▒Č╝╩ŪŽÓī”ė┌ī”ĘĮüĒšfĄ─Ż¼╗“š▀šf╩ŪÅ─Æ▀├ĶĄ─ĘĮŽ“╔ŽüĒ┐┤Ą─
ĪĪĪĪÅ─ę╗éĆĘĮŽ“╔Ž┐┤Ī░┐┐║¾Ą─Ī▒öĄ(sh©┤)ō■(j©┤)Ż¼Å─ę╗éĆĘĮŽ“┐┤Š═╩ŪĪ░┐┐Ū░Ą─Ī▒Ż¼Ū░║¾▓╗╩ŪĮ^ī”Ą─ĪŻ
ĪĪĪĪ╚ńŽ┬ā╔éĆĮžłD╩ŪBśõ╦„ę²ĮY(ji©”)śŗ(g©░u)Ą─┤ų┬į▒Ē¼F(xi©żn)ą╬╩ĮŻ¼╝┘╚ń─┐ś╦(bi©Īo)öĄ(sh©┤)ō■(j©┤)Ą─╬╗ų├╣╠Č©Ą─ŪķørŽ┬Ż¼╦∙ų^Ą─Ī░┐┐║¾Ī▒╩ŪŽÓī”┼cÅ─ū¾Ž“ėęüĒšfĄ─Ż╗
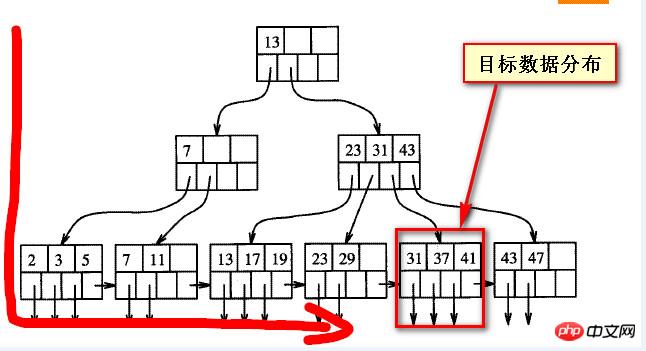
╚ń╣¹Å─ėꎓū¾┐┤Ż¼ų«Ū░╦∙ų^┐┐║¾Ą─öĄ(sh©┤)ō■(j©┤)īŹ(sh©¬)ļH╔Ž╩ŪĪ░┐┐Ū░Ī▒Ą─ĪŻ
ĪĪĪĪų╗ę¬öĄ(sh©┤)ō■(j©┤)╩Ū┐┐Ū░Ą─Ż¼ę¬Ė▀ą¦Ą═šęĄĮ▀@▓┐Ęų?j©½n)?sh©┤)ō■(j©┤)Ż¼▀Ć╩Ū┐╔ęįĄ─ĪŻmysqlųąæ¬(y©®ng)įōę▓ėąŅÉ╦Ųė┌sqlserverųąĄ─š²Ž“Ż©forwardedŻ®║═Ę┤Ž“Æ▀├ĶŻ©backwardŻ®Ą─ū÷Ę©ĪŻ
ĪĪĪĪ╚ń╣¹ī”ė┌┐┐║¾Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▓╔ė├Ę┤Ž“Æ▀├ĶŻ¼æ¬(y©®ng)įōŠ═┐╔ęį║▄┐ņšęĄĮ▀@éĆ▓┐Ęų?j©½n)?sh©┤)ō■(j©┤)Ż¼╚╗║¾ī”šęĄĮĄ─öĄ(sh©┤)ō■(j©┤)į┌į┘┤╬┼┼ą“Ż©ascŻ®Ż¼ĮY(ji©”)╣¹æ¬(y©®ng)įō╩Ūę╗śėĄ─Ż¼
ĪĪĪĪ╩ūŽ╚üĒ┐┤ą¦╣¹Ż║ĮY(ji©”)╣¹Ė·╔Ž├µĄ─▓ķįāę╗─Żę╗śėŻ¼▀@└’āH║─Ģr0.07├ļŻ¼ų«Ū░Ą─ā╔ĘNīæĘ©Š∙│¼▀^┴╦8├ļŻ¼ą¦┬╩ėą╔Ž░┘▒ČĄ─▓ŅŠÓĪŻ
ĪĪĪĪ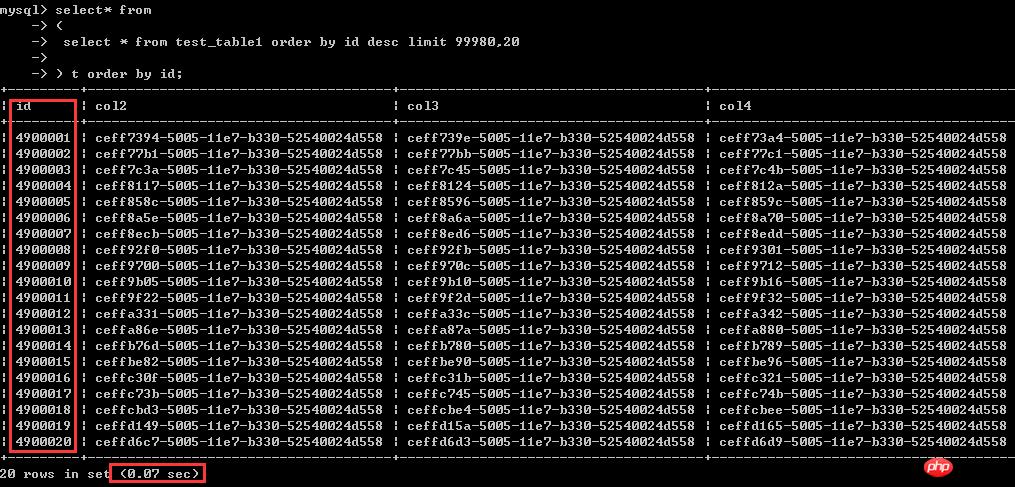
ĪĪĪĪų┴ė┌▀@éĆ╩Ū×ķ╩▓├┤Ż¼╬ęŽļĖ∙ō■(j©┤)╔Ž├µĄ─ĻU╩÷Ż¼ūį╝║æ¬(y©®ng)įō─▄ē“¾wĢ■Ą─ĄĮŻ¼▀@└’ĖĮ╔Ž▀@éĆsqlĪŻ
ĪĪĪĪ╚ń╣¹Įø(j©®ng)│Ż▓ķįā╦∙ų^Ą─┐┐║¾Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▒╚╚ńšfId▌^┤¾Ą─öĄ(sh©┤)ō■(j©┤)Ż¼╗“š▀šf╩ŪĢrķgŠSČ╚╔Ž▌^ą┬Ą─öĄ(sh©┤)ō■(j©┤)Ż¼┐╔ęį▓╔ė├Ą╣öóÆ▀├Ķ╦„ę²Ą─ĘĮ╩ĮüĒīŹ(sh©¬)¼F(xi©żn)Ė▀ą¦ĘųĒō▓ķįā
ĪĪĪĪŻ©▀@└’šłėŗ╦Ń║├öĄ(sh©┤)ō■(j©┤)╦∙į┌Ą─ĘųĒōŻ¼═¼śėĄ─öĄ(sh©┤)ō■(j©┤)Ż¼š²ą“║═Ą╣ą“ŲõŲ╩╝Ī░Ēō┤aĪ▒╩Ū▓╗═¼Ą─Ż®
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
«ö(d©Īng)ø]ėą║Y▀xŚl╝■Ż¼┼┼ą“┴ą×ķĘŪŠ█╝»╦„ę²Ą─Ģr║“Ż¼Ģ■ėą╦∙Ė─╔Ų
ĪĪĪĪ▀@└’ī”£yįć▒Ētest_table1ū÷│÷╚ńŽ┬Ė─ūā
ĪĪĪĪ1Ż¼į÷╝ėę╗éĆid_2┴ąŻ¼
ĪĪĪĪ2Ż¼įōūųČ╬╔Žäō(chu©żng)Į©ę╗éĆ╬©ę╗╦„ę²Ż¼
ĪĪĪĪ3Ż¼įōūųČ╬ė├ī”æ¬(y©®ng)Ą─ų„µIId╠Ņ│õ
ĪĪĪĪ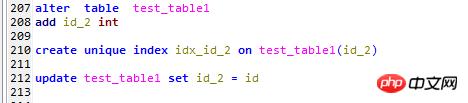
ĪĪĪĪ╔Ž├µĄ─£yįć╩Ū░┤ššų„µI╦„ę²Ż©Š█╝»╦„ę²Ż®üĒ┼┼ą“Ą─Ż¼¼F(xi©żn)į┌üĒ░┤ššĘŪŠ█╝»╦„ę²┼┼ą“Ż¼ę▓╝┤ą┬į÷Ą─▀@éĆ┴ąid_2üĒ┼┼ą“Ż¼£yįćę╗ķ_╩╝╠ߥĮĄ─ā╔ĘNĘųĒōĘĮĘ©ĪŻ
ĪĪĪĪ╩ūŽ╚üĒ┐┤Ą┌ę╗ĘNīæĘ©
ĪĪĪĪselect * from test_table1 order by id_2 asc limit 4900000,20;ł╠(zh©¬)ąąĢrķg×ķ1ĘųńŖČÓę╗³c(di©Żn)Ż¼Ģ║ŪęšJ(r©©n)Ųõ×ķ60├ļ
ĪĪĪĪ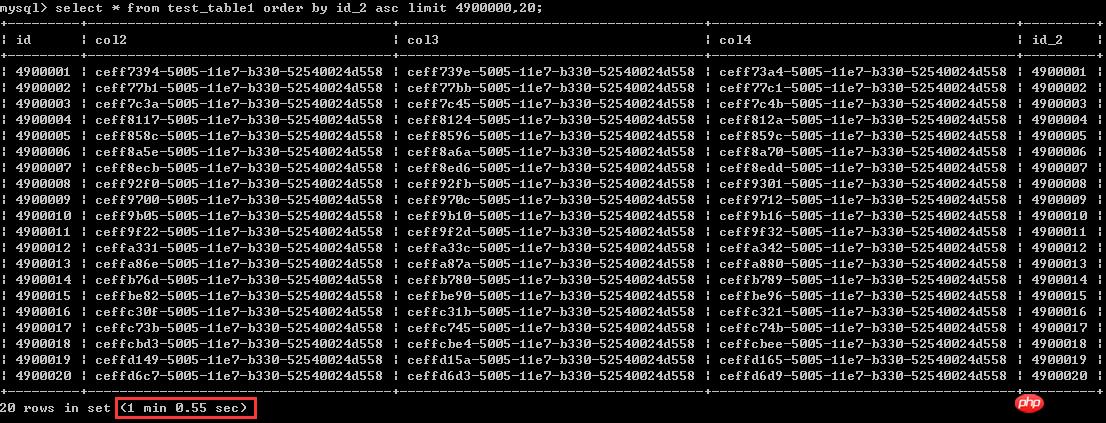
ĪĪĪĪĄ┌Č■ĘNīæĘ©
select t1.* from test_table1 t1
inner join (select id from test_table1 order by id_2 limit 4900000,20)t2 on t1.id = t2.id;ł╠(zh©¬)ąąĢrķg1.67├ļ
ĪĪĪĪ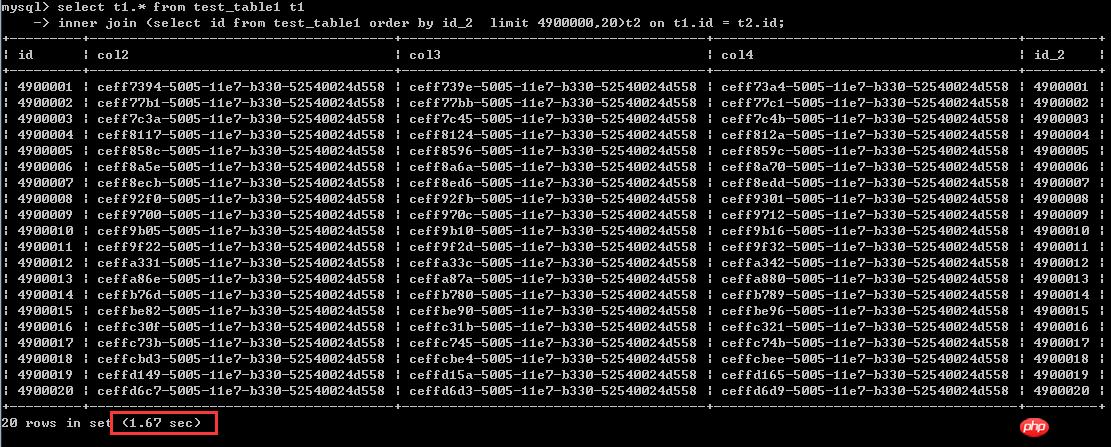
ĪĪĪĪÅ─▀@ĘNŪķørüĒ┐┤Ż¼ę▓Š═╩Ūšf┼┼ą“┴ą×ķĘŪŠ█╝»╦„ę²┴ąĄ─Ģr║“Ż¼║¾ę╗ĘNīæĘ©┤_īŹ(sh©¬)─▄┤¾Ę∙Č╚Ąž╠ß╔²ą¦┬╩ĪŻ▓Ņ▓╗ČÓėą40▒ČĄ─╠ß╔²ĪŻ
ĪĪĪĪ─Ū├┤įŁę“į┌║╬─žŻ┐
ĪĪĪĪ╩ūŽ╚üĒ┐┤Ą┌ę╗ĘNīæĘ©Ą─ł╠(zh©¬)ąąėŗäØŻ¼┐╔ęį║åå╬└ĒĮŌ×ķ▀@éĆsqlĄ─ł╠(zh©¬)ąąĢrū÷╚½▒ĒÆ▀├Ķų«║¾Ż¼╚╗║¾ųžą┬░┤ššid_2┼┼ą“Ż¼ūŅ║¾╚ĪūŅŪ░20ŚlöĄ(sh©┤)ō■(j©┤)ĪŻ
ĪĪĪĪ╩ūŽ╚╚½▒ĒÆ▀├ĶŠ═╩Ūę╗éĆĘŪ│Ż║─ĢrĄ─▀^│╠Ż¼┼┼ą“ę▓╩Ūę╗éĆĘŪ│Ż┤¾Ą─┤·ārŻ¼ę“┤╦▒Ē¼F(xi©żn)×ķąį─▄ĘŪ│ŻĄ─Ą═Ž┬ĪŻ
ĪĪĪĪ
ĪĪĪĪį┘üĒ┐┤║¾š▀Ą─ł╠(zh©¬)ąąėŗäØŻ¼╦¹╩Ū╩ūŽ╚ūėūė▓ķįāųąŻ¼░┤ššid_2╔ŽĄ─╦„ę²Ēśą“Æ▀├ĶŻ¼╚╗║¾ė├Ę¹║ŽŚl╝■Ą─ų„µIId╚ź▒Ēųą▓ķįāöĄ(sh©┤)ō■(j©┤)
ĪĪĪĪ▀@śėĄ─įÆŻ¼▒▄├Ō┴╦▓ķįā│÷üĒ┤¾┴┐Ą─öĄ(sh©┤)ō■(j©┤)╚╗║¾ųžą┬┼┼ą“Ż©Using filesortŻ®
ĪĪĪĪ╚ń╣¹┴╦ĮŌsqlserverł╠(zh©¬)ąąėŗäØĄ─ŪķørŽ┬Ż¼║¾š▀┼cŪ░š▀ŽÓ▒╚Ż¼æ¬(y©®ng)įō▀Ćėą▒▄├Ō┴╦ŅlĘ▒Ą─╗ž▒ĒŻ©sqlserverųąĮąū÷key lookup╗“š▀Ģ°║×▓ķšęĄ─▀^│╠
ĪĪĪĪ┐╔ęįšJ(r©©n)×ķ╩Ūūė▓ķįā“ī(q©▒)äė═Ōīė▒Ē▓ķįāĘ¹║ŽŚl╝■Ą─20ŚlĄ─öĄ(sh©┤)ō■(j©┤)Ą─▀^│╠╩Ūę╗éĆ┼·┴┐Ą─Ż¼ę╗┤╬ąįĄ─ĪŻ
ĪĪĪĪ
ĪĪĪĪŲõīŹ(sh©¬)Ż¼ų╗ėąį┌«ö(d©Īng)Ū░ŪķørŽ┬Ż¼ę▓Š═╩Ūšf┼┼ą“┴ą×ķĘŪŠ█╝»╦„ę²┴ąĄ─Ģr║“Ż¼Ė─īæ║¾Ą─sql▓┼─▄╠ß╔²ĘųĒō▓ķįāĄ─ą¦┬╩ĪŻ
ĪĪĪĪ╝┤▒Ń╚ń┤╦Ż¼┤╦ĘĮ╩ĮĪ░ā×(y©Łu)╗»Ī▒▀^Ą─ĘųĒōšZŠõŻ¼▀Ć╩Ū┼c╚ńŽ┬īæĘ©Ą─ĘųĒōą¦┬╩ėą▒╚▌^┤¾Ą─▓ŅäeĄ─
ĪĪĪĪ╔Ž├µę▓┐┤ĄĮ┴╦Ż¼ĘĄ╗ž═¼śėĄ─öĄ(sh©┤)ō■(j©┤)Ż¼╚ńŽ┬Ą─▓ķįā╩Ū0.07├ļŻ¼▒╚▀@└’Ą─1.67├ļ▀Ć╩ŪĖ▀2éĆöĄ(sh©┤)┴┐╝ēĄ─
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
ĪĪĪĪ┴Ē═Ōę╗éĆŻ¼Žļ╠ߥĮĄ─å¢Ņ}Š═╩ŪŻ¼╚ń╣¹Įø(j©®ng)│ŻąįĘųĒō▓ķįāŻ¼▀Ćę¬░┤šš─│ĘNĒśą“Ż¼─Ū├┤×ķ╩▓├┤▓╗į┌▀@éĆ┴ą╔ŽĮ©┴óę╗éĆŠ█╝»╦„ę²ĪŻ
ĪĪĪĪ▒╚╚ńšZŠõūįį÷IdĄ─Ż¼╗“š▀Ģrķg+Ųõ╦¹ūųČ╬┤_▒Ż╬©ę╗ąįĄ─Ż¼mysqlĢ■į┌ų„µI╔Žūįäėäō(chu©żng)Į©Š█╝»╦„ę²ĪŻ
ĪĪĪĪ╚╗║¾ėą┴╦Š█╝»╦„ę²Ż¼Ī░┐┐Ū░Ī▒┼cĪ░┐┐║¾Ī▒āHāH╩Ūę╗éĆŽÓī”Ą─▀ē▌ŗ╔ŽĄ─Ė┼─Ņ┴╦,╚ń╣¹ČÓöĄ(sh©┤)Ģr║“╩ŪŽļĄ├ĄĮĪ░┐┐║¾Ī▒╗“š▀▌^ą┬Ą─öĄ(sh©┤)ō■(j©┤)Ż¼Š═┐╔ęį▓╔ė├╔Ž╩÷īæĘ©Ż¼
«ö(d©Īng)┤µį┌║Y▀xŚl╝■Ą─ŪķørŽ┬Ż¼ĘųĒō▓ķįāĄ─ā×(y©Łu)╗»
ĪĪĪĪ▀@ę╗▓┐ĘųŽļ┴╦ŽļŻ¼Ūķør╠½Å═(f©┤)ļs┴╦Ż¼║▄ļyĖ┼└©│÷üĒę╗ĘNĘŪ│ŻŠ▀ėą┤·▒ĒąįĄ─░Ė└²Ż¼ę“┤╦Š═▓╗▀^ČÓĄžū÷£yįć┴╦ĪŻ
ĪĪĪĪselect * from t where *** order by id limit m,n
ĪĪĪĪ1Ż¼▒╚╚ń╦ó▀xŚl╝■▒Š╔ĒŠ═║▄Ė▀ą¦Ż¼ę╗▀^×V│÷üĒāH╩ŻŽ┬║▄╔┘ę╗▓┐Ęų?j©½n)?sh©┤)ō■(j©┤)Ż¼─Ū├┤Ė─▓╗Ė─īæsqlęŌ┴xę▓▓╗┤¾Ż¼ę“?y©żn)ķ║Y▀xŚl╝■▒Š╔ĒŠ═┐╔ęįū÷ĄĮ║▄Ė▀ą¦Ą─║Y▀x
ĪĪĪĪ2Ż¼▒╚╚ń╦ó▀xŚl╝■▒Š╔Ēū„ė├▓╗┤¾Ż©▀^×V║¾öĄ(sh©┤)ō■(j©┤)┴┐ę└╚╗Š▐┤¾Ż®Ż¼▀@ĘNŪķørŲõīŹ(sh©¬)ėų╗žĄĮ┴╦▓╗┤µį┌║Y▀xŚl╝■Ą─ŪķørŻ¼▀Ćėą╚ĪøQė┌╚ń║╬┼┼ą“Ż¼š²ą“▀Ć╩ŪĄ╣ą“Ą╚Ą╚
ĪĪĪĪ3Ż¼▒╚╚ń║Y▀xŚl╝■▒Š╔Ēū„ė├▓╗┤¾Ż©▀^×V║¾öĄ(sh©┤)ō■(j©┤)┴┐ę└╚╗Š▐┤¾Ż®Ż¼ę¬┐╝æ]Ą─ę╗éĆ║▄īŹ(sh©¬)ļHĄ─å¢Ņ}╩ŪöĄ(sh©┤)ō■(j©┤)Ęų▓╝Ż¼
ĪĪĪĪĪĪĪĪöĄ(sh©┤)ō■(j©┤)Ą─Ęų▓╝ę▓Ģ■ė░ĒæĄ─sqlĄ─ł╠(zh©¬)ąąą¦┬╩Ż©sqlserverųąĄ─Įø(j©®ng)ÜvŻ¼mysqlæ¬(y©®ng)įō▓Ņäe▓╗┤¾Ż®
ĪĪĪĪ4Ż¼▒Š╔Ē▓ķįā▒╚▌^Å═(f©┤)ļsĄ─ŪķørŽ┬Ż¼║▄ļyšfė├─│ĘNĘĮ╩ĮŠ═┐╔ęį▀_(d©ó)ĄĮĖ▀ą¦Ą──┐Ą─
ĪĪĪĪŪķørįĮÅ═(f©┤)ļsŻ¼įĮ╩Ūļyęį┐éĮY(ji©”)│÷üĒę╗ĘN═©ė├ąįĄ─ęÄ(gu©®)┬╔╗“š▀šf╩ŪĘĮĘ©Ż¼ę╗ŪąČ╝ę¬ęįŠ▀¾wŪķørüĒ┐┤┤²Ż¼║▄ļyŽ┬ę╗éĆČ©šōĪŻ
ĪĪĪĪ▀@└’ī”ė┌▓ķįā╝ė╔Ž║Y▀xŚl╝■Ą─ŪķørŻ¼Š═▓╗ū÷ę╗ę╗Ęų╬÷┴╦Ż¼▓╗▀^┐╔ęį┐ŽČ©Ą─╩ŪŻ¼├ōļx┴╦īŹ(sh©¬)ļHł÷Š░Ż¼┐ŽČ©ø]ėąę╗éĆ╣╠╗»Ą─ĘĮ░ĖĪŻ
ĪĪĪĪ┴Ē═ŌŻ¼ī”ė┌▓ķįā«ö(d©Īng)Ū░ĒōöĄ(sh©┤)ō■(j©┤)Ģr║“Ż¼└¹ė├╔Žę╗Ēō▓ķįāĄ─ūŅ┤¾ųĄū÷║Y▀xŚl╝■Ż¼ę▓┐╔ęį║▄┐ņĄ╬šęĄĮ«ö(d©Īng)Ū░ĒōĄ─öĄ(sh©┤)ō■(j©┤)Ż¼▀@śė«ö(d©Īng)╚╗ø]ėąå¢Ņ}Ż¼Ą½▀@ī┘ė┌┴Ē═Ōę╗éĆū÷Ę©Ż¼▓╗į┌▒Š╬─ėæšōų«┴ąĪŻ
┐éĮY(ji©”)
ĘųĒō▓ķįāŻ¼įĮ┐┐║¾įĮ┬²Ą─ŪķørŻ¼īŹ(sh©¬)ätī”ė┌Bśõ╦„ę²üĒšfŻ¼┐┐Ū░┼c┐┐║¾╩Ūę╗éĆ▀ē▌ŗ╔ŽŽÓī”Ą─Ė┼─ŅŻ¼ąį─▄╔ŽĄ─▓Ņ«ÉŻ¼╩Ū╗∙ė┌Bśõ╦„ę²ĮY(ji©”)śŗ(g©░u)ęį╝░Æ▀├ĶĘĮ╩ĮėąĻP(gu©Īn)Ą─.
╚ń╣¹╝ė╔Ž║Y▀xŚl╝■Ż¼ŪķørīóūāĄ├Ė³╝ėÅ═(f©┤)ļsŻ¼▀@éĆå¢Ņ}į┌SQL ServerųąĄ─įŁ└Ēę▓╩Ūę╗śėĄ─Ż¼▒ŠüĒę▓į┌SQL Serverųąū÷┴╦£yįćĄ─Ż¼▀@└’Š═▓╗ųžÅ═(f©┤)┴╦ĪŻ
«ö(d©Īng)Ū░▀@ĘNŪķørŻ¼┼┼ą“┴ą▓╗ę╗Č©Ż¼▓ķįāŚl╝■▓╗ę╗Č©Ż¼öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓╗ę╗Č©Ż¼Š═║▄ļyė├ę╗ĘN╠žČ©Ą─ĘĮĘ©üĒīŹ(sh©¬)¼F(xi©żn)Ī░ā×(y©Łu)╗»Ī▒Ż¼┼¬▓╗║├▀ĆŲĄĮ«ŗ╔▀╠ĒūŃĄ─Ė▒ū„ė├ĪŻ
ę“┤╦į┌ū÷ĘųĒōā×(y©Łu)╗»Ą─Ģr║“Ż¼ę╗Č©ę¬Ė∙ō■(j©┤)Š▀¾wĄ─ł÷Š░üĒū÷Ęų╬÷Ż¼ĘĮĘ©ę▓▓╗ę╗Č©ų╗ėąę╗ĘNŻ¼├ōļxīŹ(sh©¬)ļHł÷Š░Ą─ĮY(ji©”)šōŻ¼Č╝╩Ū│ČĀ┘ūėĪŻ
╬©ėą┼¬ŪÕ│■▀@éĆå¢Ņ}Ą─üĒ²ł╚ź├}Ż¼▓┼─▄ė╬╚ąėąėÓĪŻ
ę“┤╦éĆ╚╦ī”ė┌öĄ(sh©┤)ō■(j©┤)Ī░ā×(y©Łu)╗»Ī▒Ą─ĮY(ji©”)šōŻ¼ę╗Č©╩ŪŠ▀¾wå¢Ņ}Š▀¾wĘų╬÷Ż¼╩Ū║▄╝╔ųM┐éĮY(ji©”)│÷üĒę╗╠ūęÄ(gu©®)ätŻ©ęÄ(gu©®)ät1,2,3,4,5Ż®Įo╚╦Ī░╠ūė├Ī▒Ż¼Ķbė┌▒Š╚╦ę▓║▄▓╦Ż¼Š═Ė³▓╗Ėę┐éĮY(ji©”)│÷üĒę╗ą®Į╠Śl┴╦ĪŻ
ĪĪĪĪ
ęį╔ŽŠ═╩ŪMySQLĘųĒōā×(y©Łu)╗»Ą─£yįć░Ė└²Ą─įö╝Ü(x©¼)ā╚(n©©i)╚▌Ż¼Ė³ČÓšłĻP(gu©Īn)ūóphpųą╬─ŠW(w©Żng)Ųõ╦³ŽÓĻP(gu©Īn)╬─š┬ŻĪ
īW(xu©”)┴Ģ(x©¬)Į╠│╠┐ņ╦┘šŲ╬šÅ─╚ļķTĄĮŠ½═©Ą─SQLų¬ūRĪŻ
